

看完上一篇利用 AI 預測來自動化招募員工流程,以減少每年上億員工離職損失,我們了解到:每個員工離職對於公司來說都是非常大的損失,不僅浪費時間與金錢,降低團隊士氣,進而影響了整體營收。即使是降低了 1% 的離職率,也能使規模 3 萬人的公司每年節省約 3 千 3 百萬美元的浪費。
那麼,究竟如何解決此問題呢?
降低離職率最有效率且不增加人力成本的方式,便是在招募期間以量化的數據科學 (data science) 方式來預測每位面試者的離職機率,進行履歷的快速篩選。製作離職預測資料模型的 5 大步驟:
- 人力資源原始資料蒐集 – 包含過去員工履歷以及性向測驗資料、過去員工履歷資料以及過去員工就職年數等
- 資料清洗/前處理
- 資料特徵處理/選擇
- 機器學習建模與優化
- 將新面試者履歷以及性向測驗資料放入第4點的模型,進行離職預測,以便履歷篩選
我們可以看到,上述的第1點及第5點會根據每個公司的資料庫形式以及決策方式有所不同,而第 2-4 點的建模過程則是通用的,因此接下來我們會介紹兩種離職預測建模的方法:
- 資料科學家手動進行資料建模 – 預計耗時一至兩個月
- 使用自動化機器學習軟體建模 – 預計耗時兩週
第一種:資料科學家手動進行資料建模
在開始介紹資料科學家的建模過程前,首先我們來了解一下資料科學家使用的工具:
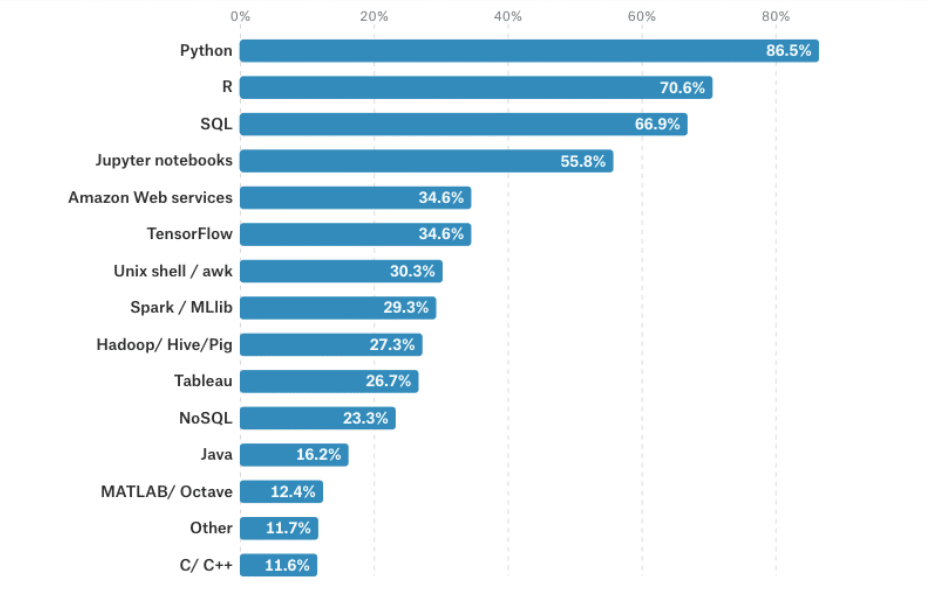
資料科學家大多使用開源程式語言 (open source programming language),如 Python、R 與其資料分析相關的套件 (library)。 以下是 Google 旗下資料科學競賽平台 – Kaggle針對參賽者使用的程式語言做的調查,可以看到 Python 跟 R 是資料科學家使用最多的 2 個語言。另外,Jupyter notebooks 也是很常用的交互式計算環境,支援許多語言如 Python。
接下來讓我們來看資料科學家進行建模的過程:
01 資料清洗/前處理 Data Cleaning/Pre-processing
當資料科學家收到過去員工資訊以及離職資訊後,資料科學家必須寫 Python 程式去除或填補空白值與做資料前處理,例如 one-hot encoding 與標準化 (standardization)。
資料標準化後可以降低特徵極端值對於某些演算法模型結果的影響,例如許多分類模型 (classifier) 是基於計算兩點的距離差,如果其中一個特徵距離差太大會對此模型的預測結果造成過多影響。
在前處理階段,很常使用的 Python 庫包括 NumPy 與 Pandas。NumPy 用來處理基本的科學計算,包括矩陣運算跟線性代數。Pandas 是建立在 NumPy 之上的庫,主要是用來處理表格 (DataFrame) 類型的資料做清洗跟運算。
02 資料特徵處理/選擇 Feature Engineering/Selection
接下來便是做特徵處理跟選擇,特徵處理 (feature engineering) 的主要目的是把原始人員資料轉變成後續演算法可以使用的特徵格式,接著只選擇對預測人員離職有影響的特徵,並移除不重要的特徵。
選擇特徵可以用統計的方法、依照各模型的不同方法或是 grid search (最需要計算效能的)。在這個過程中也必須做探索性資料分析 (exploratory data analysis),通常使用資料視覺化 (visualization) 來得出特徵與特徵的關係或是特徵與人員離職的關係。這部分可以用 matplotlib 與 Seaborn 來視覺化履歷表資訊與離職的圖表,分析是否某些資料特徵直接影響人員是否會離職。
03 機器學習建模與優化 Model Building and Optimization
終於到了最後一個步驟:機器學習建模與優化。
此步驟一般是使用 Python scikit-learn 模組,用內建的演算法建模並評估模型表現,演算法例如Logistic Regression, Random Forest, XGBoost。
以上三步驟將進行不斷地重複,直到資料科學家認為找到了足夠準確的模型。如果結果不夠好,則必須回到上一步的特徵處理與選擇之後再建一個模型,或是測試不同的演算法。換另一個演算法的話,模型參數調整也是一個反覆測試的步驟,並且進行交叉驗證 (cross-validation),以確保模型預測的穩定性。這幾個步驟也是資料科學家花最多時間的地方。可能一晃眼就一兩個月過去了。
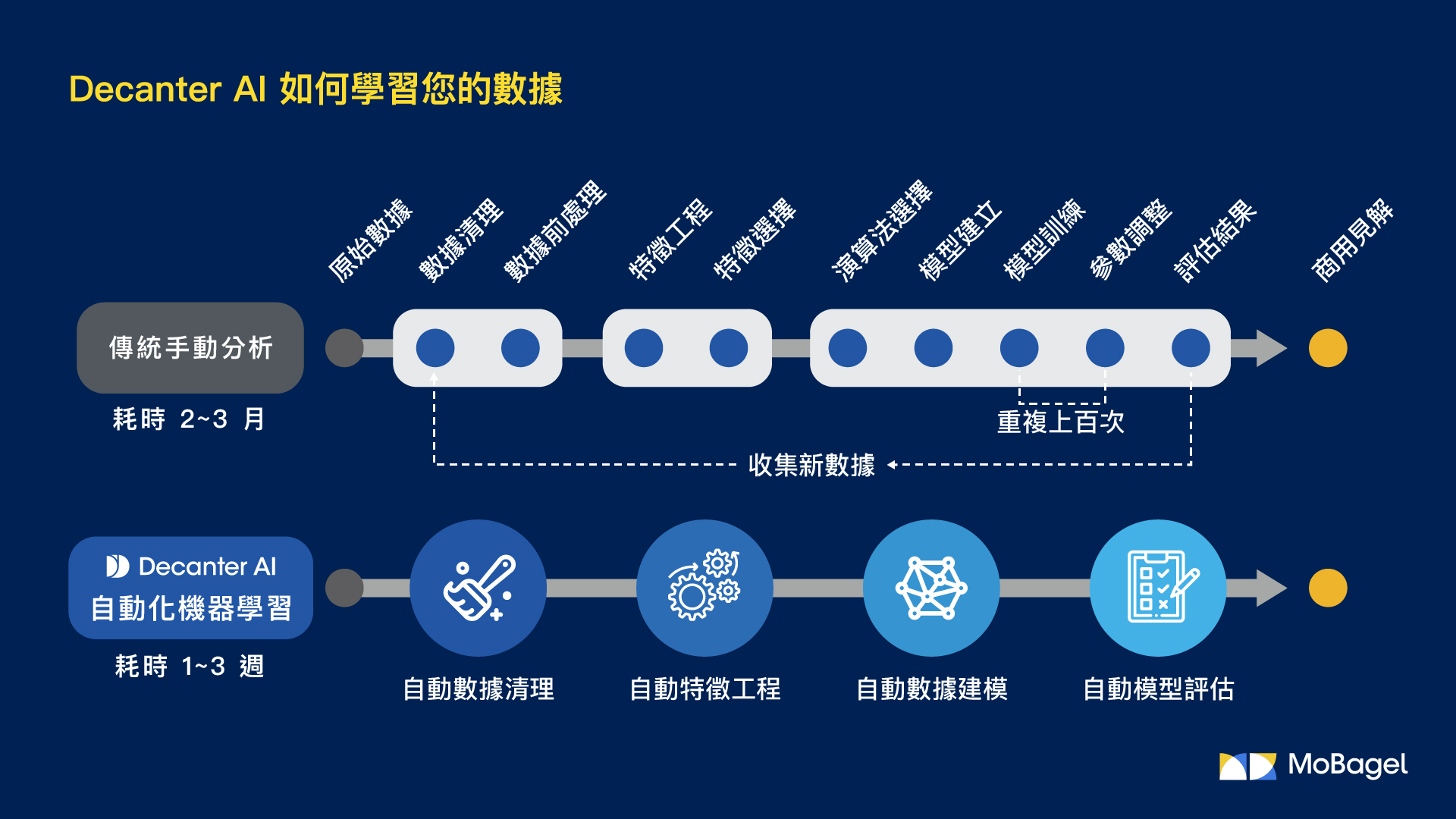
看完以上,相信不是資料科學家的讀者會覺得被專有名詞淹沒了。因此,我們接下來便是介紹如何用自動化機器學習軟體來跑完以上步驟。
第二種:使用自動化機器學習軟體建模
如果公司內部沒有上述這些相關技術,必須考慮導入容易使用的預測技術,例如自動化機器學習 (AutoML)。如此一來,不僅只需要少數的人力資源分析團隊使用,還可以為公司建立獨立於使用者技能的一致性預測結果。
我們拿 Decanter AI 為例,使用者只需要滑鼠按幾下就可以在幾分鐘內建好一個模型。下面使用 IBM Watson 提供的員工離職資料集1來做實際操作。
上傳完 CSV 資料之後馬上可以知道這個資料有多少個特徵,有多少列。很快知道這個資料集的大小。除此之外,Decanter AI 還可以自動產生相關矩陣 (correlation matrix),能夠視覺化的顯示各特徵之前的關係。
我們馬上便來進入最後的訓練模型階段:選取分類 (classification) 問題後,將 ”Attrition” (離職)放到 “Target” 欄位,其他的特徵全部丟進 “Features” 欄位,並讓全部設定都為 “Auto”。
只要按下 “Build Model”,Decanter AI 馬上就會訓練並建立一個人員離職的模型。
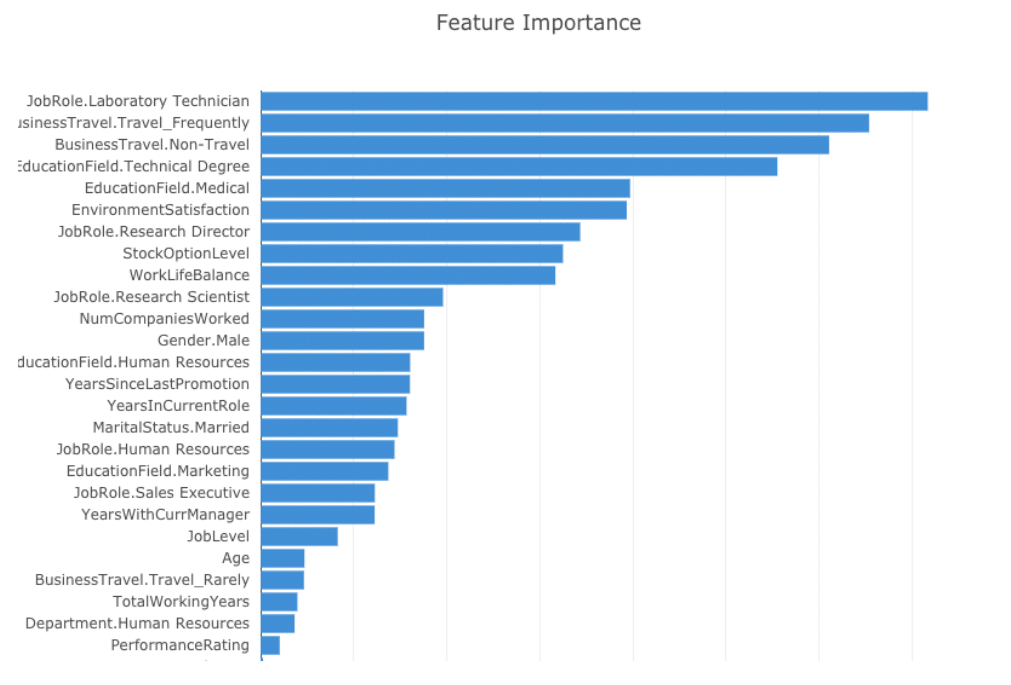
Decanter AI 只花了不到 4 分鐘就建好了一個人員離職模型,而且不需要寫任何程式碼。而且自動產生的 Feature Importance 表可以看出哪一些特徵對於預測人員離職結果影響最大。資料科學家可以用這個結果去解釋且思考解決離職率的策略。
另外,Decanter AI 還可以顯示自動跑過的模型以及他們的排名(排名是根據選擇的 Evaluator 決定)。
有了Decanter AI ,只需要短短幾分鐘就可以建立一個模型,讓團隊有更多時間解決其他更重要的事項,提高整體公司運營效率。
看完以上手動與自動建模的流程區別,讀者可以依據自己的所熟悉的工具,以及擁有的時間來決定要如何進行資料建模。接下來推薦讀者看:如何使用自動化機器學習(AutoML) 進行更準更快的數據分析 並節省成本至傳統1/3